
Wykorzystujemy na swojej stronie internetowej zarówno niezbędne pliki cookies w ramach zapewnienia możliwości poprawnego korzystania ze strony oraz poprawy jej funkcjonowania, a także opcjonalne pliki funkcjonalne i statystyczno-analityczne, na które możesz wyrazić zgodę lub odrzucić ich wykorzystywanie podczas swojej sesji na stronie internetowej. Wszystkie niezbędne pliki cookies wykorzystywane do poprawnego funkcjonowania strony oraz ulepszenia jej są plikami sesyjnymi, a pliki funkcjonalne i statystyczno-analityczne są plikami stałymi, których okres przechowywania jest określony odgórnie przez ich dostawców. Informacje o okresie przechowywania są zawarte w widoku szczegółowym plików cookies.
W ostatnich latach pojawiło się mnóstwo narzędzi wspomagających pracę deweloperów. Narzędzia CLI, które jedną komendą potrafią postawić całe środowisko deweloperskie. Zintegrowane środowiska deweloperskie, które podpowiadają, jak napisać kod w danym miejscu lub potrafią całkowicie wygenerować go od zera. Cała masa wtyczek, które na bieżąco śledzą twoje poczynania, aby aplikacja, którą tworzysz była optymalna i bezpieczna. Problemy, z którymi mierzyli się programiści 5, 10 lat temu teraz już praktycznie nie istnieją. Ale czy na pewno już wszystko w codziennej pracy mamy podane na tacy? Czy każdy aspekt tworzenia oprogramowania jest łatwy, szybki i przyjemny dzięki narzędziom, po które codziennie sięgamy?
Czy istnieje narzędzie, które zarządza skutecznie aplikacją mikroserwisową?
Według mnie są jeszcze obszary, które wymagają więcej od programisty niż wpisanie jednej komendy i rozpoczęcie pracy nad aplikacją. W dzisiejszych czasach rozwój programowania jest niesamowicie szybki. Ilość nowych podejść do programowania, nowych pomysłów na rozwiązywanie starych lub współczesnych problemów jest ogromna.
Klasycznym przykładem obecnego podejścia do programowania i współczesnych idei jest architektura mikroserwisowa. W bardzo dużym skrócie (to nie jest artykuł o tym czym jest architektura mikroserwisowa), aplikacja mikroserwisowa jest aplikacją, w której każdy jej moduł jest osobnym bytem, osobnym procesem. Oczywiście te osobne byty w pełni się ze sobą komunikują, aby wypełniać powierzone im zadania. Jednak w praktyce są to niezależne aplikacje, które jedynie mają wspólny cel. W klasycznym, monolitycznym podejściu, pomimo że każdy moduł był osobną funkcją, klasą lub całym osobnym folderem w katalogu, to jednak zawsze był integralną częścią projektu. Jeden proces, jedno repozytorium kodu, jeden problem (wyzwanie). Wyobraźmy sobie teraz, że musimy tworzyć 10 lub 20 takich aplikacji jednocześnie. Mamy mnóstwo narzędzi ułatwiających prace nad jedną aplikacją, ale czy mamy narzędzie, które nam pomaga w pracy nad 20 aplikacjami?
Wyobraźmy sobie sytuację, w której mamy aplikację, która składa się z 5 serwisów. Naszym zadaniem jest wprowadzenie zmiany do jednego z nich i sprawdzenie czy wszystko ze sobą współpracuje tak jak należy. Najprościej jest pobrać lokalnie wszystkie serwisy i uruchomić je jako niezależne procesy. Rozwiązanie najprostsze, ale już chyba sobie wszyscy wyobrazili jak bardzo niewygodne. Już przy 5 serwisach musimy uruchomić 5 terminali. Kontrolować w każdym z nich, czy wszystko działa jak należy. Musimy też pilnować, aby na naszym hoście nie wystąpił konflikt portów i jeżeli serwisy udostępniają swoje usługi na tych samych portach, to we wszystkich usługach należy te porty zmodyfikować. Jeżeli uruchomimy je wszystkie w trybie deweloperskim, który zużywa dużo więcej zasobów niż produkcyjny, to możemy doprowadzić do sytuacji, gdzie nasza lokalna maszyna zacznie mieć problemy z wydajnością.
Z drugiej strony, jeżeli postanowimy uruchomić serwisy w trybie produkcyjnym, musimy przejść po nich wszystkich, aby każdy serwis został najpierw zbudowany. W skrócie: cała masa problemów (wyzwań). Nie spotkałem się jeszcze z narzędziem, które zaadresowałoby tego typu kwestie. Zatem jedyną rzeczą jaka pozostała mi w codziennej pracy nad aplikacjami mikroserwisowymi to rozwiązanie tego osobiście. W tym artykule postaram się podzielić z wami swoimi przemyśleniami oraz rozwiązaniami, które udało mi się wypracować w całym tym procesie.
Jak radzić sobie z zarządzaniem wieloma mikroserwisami?
Najlepszym, możliwym rozwiązaniem, które pierwsze przyszło mi do głowy jest Docker. Docker to narzędzie i platforma do konteneryzacji, które umożliwia programistom tworzenie, uruchamianie i zarządzanie aplikacjami w izolowanych środowiskach znanymi jako „kontenery”. Kontenery to lekkie, przenośne i samowystarczalne jednostki. Zawierają one wszystko, co potrzebne do uruchomienia aplikacji, włącznie z kodem, zależnościami, bibliotekami i konfiguracją systemu. Każdy z naszych serwisów może być takim kontenerem, a jego uruchomienie może zostać zautomatyzowane dzięki narzędziu Docker Compose. Docker Compose to narzędzie, dzięki, któremu możemy zdefiniować w jednym pliku YAML konfiguracje wielu kontenerów i uruchomić jako jedną aplikację. Dzięki Docker Compose mamy również zapewnioną komunikację między kontenerami za pomocą wbudowanych mechanizmów networkingu. Powoduje to, że ilość pracy jaką musimy wykonać do uruchomienia aplikacji sprowadza się do minimum.
No dobrze, teraz pojawia się pytanie jak to wszystko wykorzystać do efektywnej pracy dewelopera przy tworzeniu aplikacji mikroserwisowej. Jako przykład do ilustracji zalet środowiska dockerowego stworzyłem małą aplikację, która składa się z dwóch prostych serwisów napisanych w Node.js oraz systemu kolejkowego RabbitMQ. Poniżej przedstawiam plik docker-compose.yaml, który definiuje tę aplikację.
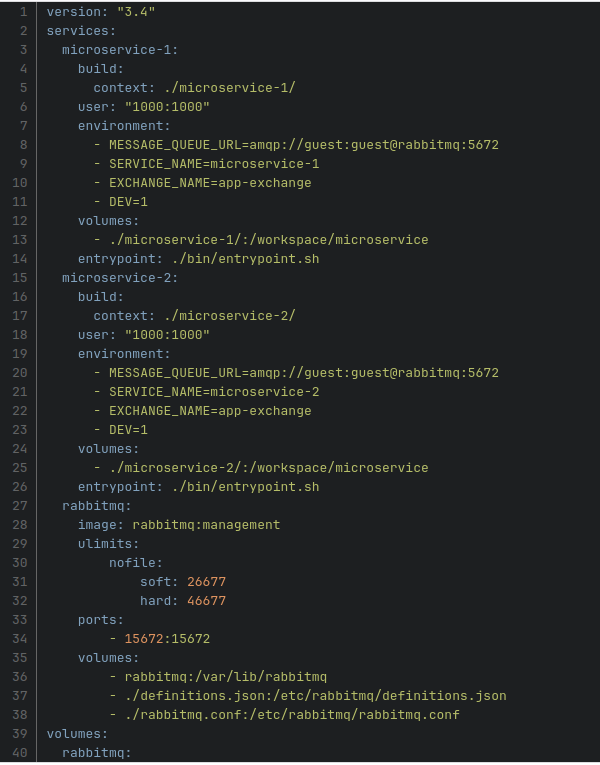
Aby uruchomić aplikację, należy w terminalu wpisać polecenie “docker-compose up”. Aplikacja polega na wysyłaniu dwóch komend. Pierwsza z nich to komenda “introduce_yourself”, która spowoduje, że serwis, który ją odebrał przedstawi się za pomocą terminala. Druga z nich to komenda “introduce_your_friend”, która spowoduję, że serwis, który ją odbierze “poprosi” drugi z serwisów, aby ten się przedstawił w terminalu. Do wysłania komend użyjemy wbudowany panel administratora RabbitMQ, który został udostępniony pod adresem localhost:15672 (docker-compose.yaml, konfiguracja rabbitmq, sekcja ports). Po wysłaniu do pierwszego serwisu obu komend widzimy w terminalu poprawne wiadomości.
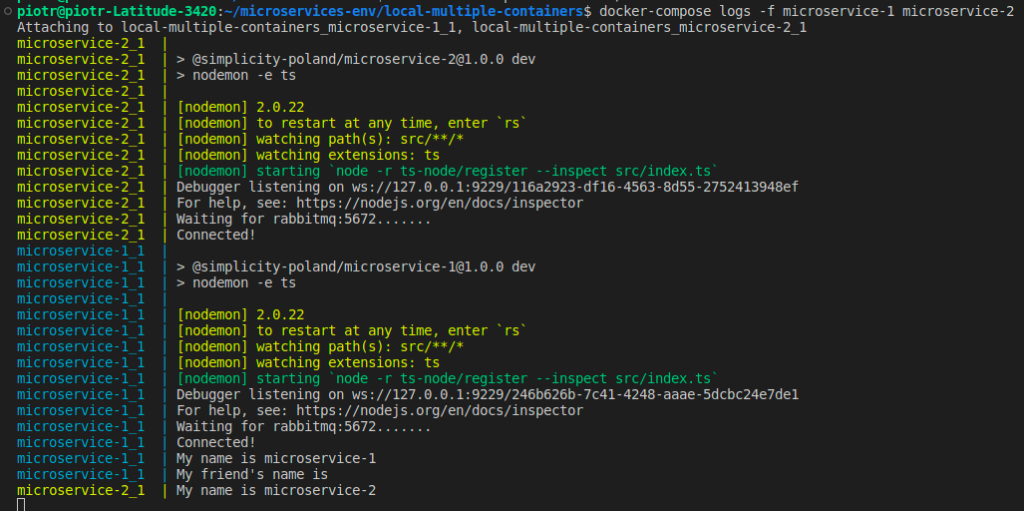
Kolejną zaletą użycia Docker Compose jest to, że w jednym miejscu możemy zagregować wszystkie logi obecne w aplikacji. W tym przypadku użyliśmy polecenia “docker-compose logs –f microservice-1 microservice-2″. Flaga “-f” oznacza, że nasze logi będą śledzone na bieżąco, a “microservice-1 microservice-2″ to dowolna lista wymienionych serwisów, obecnych w naszej aplikacji.
OK. Wiemy już jak uruchomić aplikację, jak sprawdzić jej logi i jak jej użyć. Teraz nasuwa się pytanie, co się stanie, gdy coś zmienimy w kodzie? Tutaj z pomocą przychodzą nam 2 tryby, w których mogą pracować nasze kontenery: deweloperski i produkcyjny. Jedna ze zmiennych środowiskowych użyta we wcześniej wspomnianym pliku konfiguracyjnym docker-compose.yaml (zmienna DEV), dyktuje kontenerowi jakiej strategii powinien użyć. W przypadku gdy ta zmienna jest równa 0, kontener wywoła instrukcję build, a następnie uruchomi zbudowaną wersję. W przypadku, gdy zmienna będzie równa 1, kontener uruchomi się w trybie deweloperskim. Kod odpowiedzialny za tę logikę znajduje się w skrypcie, który docker-compose używa do uruchomienia kontenera (docker-compose.yaml, konfiguracja serwisów, sekcja entrypoint). Poniżej przedstawiam zawartość tego skryptu.
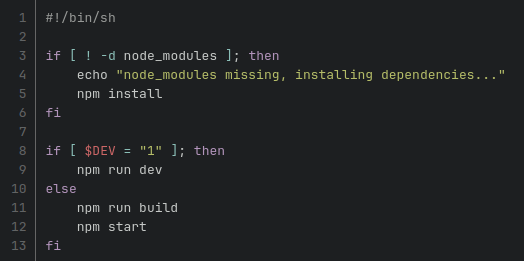
Wracając do wyżej postawionego pytania. Jeżeli kontener jest w trybie deweloperskim to każda zmiana w kodzie powoduje zrestartowanie procesu. Nowy kod natomiast zostaje natychmiast zastosowany w aplikacji. Jeżeli kontener działa w trybie produkcyjnym, zmiany w kodzie są niewidoczne dla aplikacji, gdyż raz zbudowana wersja nie ulega zmianie.
Może teraz pojawić się kolejne pytanie – po co uruchamiać kontenery w trybie produkcyjnym? Powody są dwa. Pierwszym z nich jest to, że kontener uruchomiony z serwisem w trybie produkcyjnym zużywa dużo mniej zasobów niż ten uruchomiony w trybie deweloperskim. Przy większej aplikacji, która posiada dużo więcej serwisów niż 2, lokalna maszyna może zacząć mieć problemy ze zbyt dużym zużyciem zasobów, jeżeli wszystkie serwisy będą w trybie deweloperskim. Drugim powodem, dla którego warto jest uruchamiać kontenery w trybie produkcyjnym jest to, że taka praca (jak sama nazwa wskazuje) najbardziej odpowiada realnym warunkom pracy aplikacji. Są sytuacje, w których dany serwis działa poprawnie w trybie deweloperskim, a w trybie produkcyjnym pojawiają się niespodziewane błędy. Gdy widzimy, że wszystko działa tak jak trzeba, a jedynym serwisem w trybie deweloperskim jest ten, nad którym aktualnie pracujemy, możemy mieć pewność, że po faktycznym wdrożeniu wszystko będzie działać.
A co jeśli to za mało i nie rozwiązuje wszytkich problemów tworzenia aplikacji mikroserwisowej
Przy tworzeniu dużych aplikacji mikroserwisowych lub przy tworzeniu aplikacji o charakterystyce workerów do ciężkich zadań obliczeniowych, uruchomienie nawet całej aplikacji we wcześniej wspomnianym trybie produkcyjnym może doprowadzić do znacznego obciążenia naszej maszyny lokalnej. Co wtedy możemy zrobić?
Jeżeli pracujemy w firmie, która posiada własne zasoby hardware’owe to jest jedno rozwiązanie, które pozwoli połączyć wcześniej przedstawione środowisko deweloperskie z zasobami hardware’owymi naszej firmy. Na potrzeby tego artykułu załóżmy, że mamy w chmurze swój własny klaster Kubernetes, gdzie mamy wdrożoną aplikację na potrzeby testowe/deweloperskie. Może to być oczywiście każde inne środowisko wdrożeniowe, ale do tego przykładu musiałem coś wybrać. Wszystkie pliki z konfiguracją zasobów Kubernetesa znajdują się również w repozytorium kodu. Poniżej przedstawiam lekko zmodyfikowany plik docker-compose.yaml
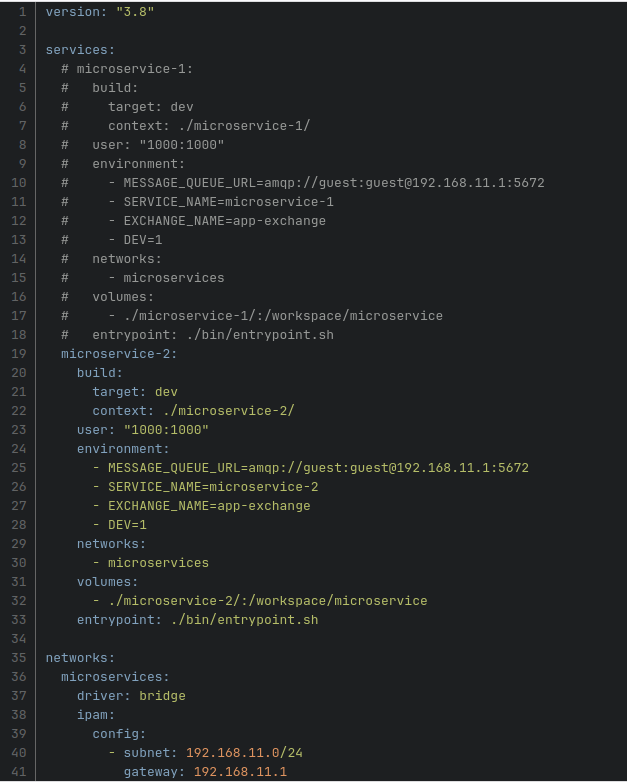
Teraz po kolei. Pierwszą rzeczą jaka się zadziała jest to, że zniknął kontener odpowiedzialny za system kolejkowy. Teraz cały system kolejkowy znajdzie się w środowisku chmurowym. Podobnie rzecz ma się z pierwszym mikroserwisem. Teraz nie będzie on podlegał pracom deweloperskim, więc nie ma potrzeby uruchamiania kontenera z tym serwisem. Użyjemy serwisu, który jest już w środowisku chmurowym. Na samym dole naszego pliku konfiguracyjnego doszła nowa sekcja “networks”.
W tej sekcji zdefiniowaliśmy sieć, której mają używać kontenery do komunikowania się między sobą. Nadaliśmy tej sieci adres, maskę oraz adres bramki. Jeżeli nie podamy tych wartość, Docker stworzy sieć domyślną o losowych parametrach. My musimy znać te parametry z góry, więc ta sekcja w pliku konfiguracyjnym jest konieczna. Każdy z serwisów dostał dodatkowo nową sekcję (networks), w której definiujemy do jakich sieci te serwisy należą. Teraz, kiedy już mamy zdefiniowane nowe środowisko deweloperskie pozostaje tylko jedna rzecz. Należy przekierować port systemu kolejkowego znajdującego się w chmurze na adres bramki naszej sieci dockerowej. Dzięki temu każdy z serwisów łącząc się na adres bramki oraz odpowiedni port, będzie miał dostęp do aplikacji. W przypadku Kubernetesa należy w terminalu użyć narzędzia CLI kubectl oraz polecenia “port-forward”.
Czy Docker ma jeszcze jakieś inne zalety ....
Aplikacje mikroserwisowe są w obecnie bardzo popularne i prędzej czy później, każdego z nas spotka problem dewelopmentu takiej aplikacji. Myślę więc, że osoby podejmujące się tworzenie aplikacji mikroserwisowej, powinny posiadać w swoim arsenale wiedzy umiejętność obsługi środowisk kontenerowych. Wyżej wymienione sposoby organizacji środowiska deweloperskiego za pomocą narzędzia Docker to tylko początek długiej listy korzyści, jakie możemy osiągnąć. Należy zwrócić uwagę, że pisząc aplikację mikroserwisową, rzadko pracujemy w pojedynkę. Najczęściej jesteśmy częścią większego zespołu, którego deweloperzy mogą posiadać różne maszyny, różne konfiguracje tych maszyn a nawet różne systemy operacyjne. Klasyczny problem po tytułem “Dziwne, u mnie działa…”, w przypadku aplikacji mikroserwisowych jest niemal nieunikniony. Tymczasem korzystając ze środowiska deweloperskiego w kontenerach, takiego problemu nie ma. Jeżeli uruchamiamy ten sam obraz na różnych maszynach, zawsze uzyskamy takie same środowisko. Sytuacje, w których na jednej maszynie aplikacja działa, a na drugiej mamy problemy są ultrarzadkie.
Jeszcze jednym plusem pracy na środowisku dockerowym, który bardzo lubię, jest to, że mój komputer jest się bardzo „czysty”. Nie muszę instalować wszystkich środowisk czy baz danych lokalnie. Node.js, Python, PostgreSQL, MongoDB i cała masa innych rzeczy, które wcześniej musiałem instalować lokalnie, teraz znajduje się wyłącznie w kontenerze. Uruchamiam kontener, mam to co chcę, usuwam kontener, wszystko znika. I to wszystko za pomocą jednej komendy. Nic więcej. Gorąco polecam deweloperom eksperymentowanie z Dockerem. Jeżeli nasz sposób tworzenia środowiska deweloperskiego komuś nie przypada do gustu, to należy zaznaczyć, że jest to tylko jedna z wielu, możliwość użycia narzędzia jakim jest Docker. Każdy może dojść do swojego idealnego środowiska i o to w tym wszystkim chodzi.
Zapisz się do newslettera i bądź zawsze na bieżąco